OpenLane:配置・配線・CTSを調べてみた
OpenLane Place & Route
OpenLaneのPlace&Routeについて確認した.

P&R フロー・ステップ
禁止領域の設定等いろいろと前処理はあるが、主要なステップをチェックすると下記のようなステップで構成してある:

-
Placemnet ステップ
- グローバル配置
- リサイズ(バッファサイジング調整、リピーター挿入):シグナルライン
- 詳細配置(リーガライズ)
-
CTS(クロックツリー合成)ステップ
- クロックツリー合成
- リサイズ(バッファ調整、リピーター挿入)
-
配線 ステップ
- グローバル配線
- 詳細配線
- 配線長チェック
リサイズ
リサイズとして簡単に書いてあるが、バッファサイズの調整とリピータ・バッファ挿入を行う処理を行っている.(ほかにもいろいろ)
リピーター・バッファについては下記を見てもらうとわかりやすいだろう:
リピーターバッファ挿入
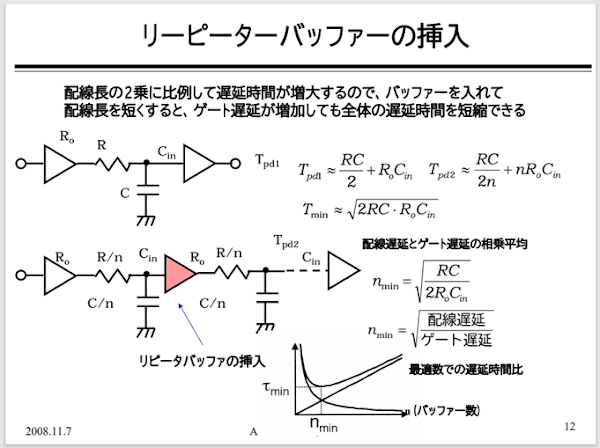
何をしているかというと、タイミングを改善するようにリピーター・バッファを挿入する機能.
リサイズは言葉の通り、ドライバビリティの調整をしている.
リサイズ処理

リサイズ関係のtclコードには、クロックツリー向けのリペアコマンドと信号向けのリペアコマンドがある.
また、グローバル配置、リサイズ、詳細配置となっているのは、グローバル配置の後でバッファ挿入をして配置を行うことで配置位置の調整やリーガライズとよぶ配置グリッドに乗せる処理まで行う.
CTS後のリサイズ処理では、タイミングのSetup/Holdを行いタイミングを収束させる処理を行う.(無理な場合はネガティブスラックが残る)
個人的には、ワイヤロードモデルで合成している場合バッファツリーが配置位置を考慮できていないためいったんバッファを消してから行いたいところだ.
ちなみに、バッファ消去コマンドは存在するのでステップを構成することは可能.
バッファ・エクスプロージョン
タイミング・ベースで最適化処理を行う場合、タイミング状態が悪いまま処理すると、バッファ挿入が爆発する場合がある.
デフォルトでは20段までに制限となっているが、それでもエクスプロージョンすると処理が破綻するためRC規定長なども含めて調整することになる.
デザイン毎に規定することが現実的だろう.
配置ステップ
グローバル配置
配置エリアの中心から移動させていくタイプのグローバル配置で初期配置が終わるとタイミングベースでのインクリメンタル最適化処理をしている模様.
SoCのような大規模マクロを使うような場合には、配置エリアが偏るため調整したほうが良い可能性はある.
CTSステップ
OpenLane/OpenROADのCTSは、シンプルツリー構造のCTSを張るようで、構成を選択できるようなオプションは無い.
シンプルツリーの場合、相対的にはインサーションディレイを小さくできるメリットはある.
CTSは別途詳しく調査する予定.
配線ステップ
Triton Router(ISPD 2018で1位らしい)がベースのようで、DRCクリーンな配線処理する詳細配線エンジン.ベンチマークは45nm/32nmでありここは他より近代的なエンジンと思われる.
とは言っても、テクノロジノードが進むとDRCルールも複雑になってくるのでDRCチェッカとの連携次第なところはあるのだろう.
RCX(寄生容量抽出)
DEF2SPEFからの変更になったようで精度良くなったということらしい.(いつから変更になったか不明)
容量抽出(OpenRCX)、フィールドソルバーを使ってリファレンス・パターンを抽出しておいて基本的にはマッチングさせると思われる.
RC抽出を簡単に言うと、
プロセス縦断面構造ファイルを与えてシリコン基板中の空間容量を演算する.
適宜フィールド・ソルバーを呼ぶのなら良い精度でRC抽出が可能だが詳細不明.(ちらっと見たところ、フィールドソルバーはモデルベースのよう)

ファクタリングはできるようなので、CCを一律Upさせることは可能だが、テクノロジ的には(上・底面より側面の容量が大きくなる100nmあたりからは必須と考えたほうが良い)クロストーク遅延計算できるようにしたい.

まとめ
いわゆる配置・配線の部分を確認してみた.実装概要は把握できたと思うが、OpenSTAがSI実装が無い点が利用時の負担となるであろう.OpenSTAにクローストーク・ディレイの実装されるとTSMCリファレンスV4.0にかなり近くなるので180/130/90nmあたりで使える可能性は増すだろう.
OpenSTAのGitHubをのぞいてみたが、デベロッパーはPRはあまり好きじゃないコメントがあるため、SIを実装してPR出すよりはフォークして作ったほうが良いように思える.